
Comparing Text-To-Image Models and Their Use Cases.


We are in mid-January, and the AI space has already delivered a mind-blowing number of exciting developments. Yesterday, OpenAI announced ‘Tasks’, a feature that allows users to set intelligent reminders. This is the first time people are going to be ‘contacted’ by an LLM instead of contacting the LLM. As such, it opens new possibilities for what some people are already calling ‘ambient AI’.
An ambient AI is akin to a computer daemon — a background process that performs tasks invisibly and only interacts with the user when necessary. It’s an AI that runs in the background, does a bunch of interesting tasks on your behalf, and then only updates you when necessary so you can take data-driven decisions.
We are in the early days, so don’t get excited too much. Still, this is a change I have been waiting for. Doesn’t it bother you that you are always the one initiating contact with AIs ? What if the AI can just reach out to you and say: “Hey, I noticed you recently worked on A and spent time studying B. It’s 9pm, I think it would be great for you to learn about C, to become more effective at A” ? Wouldn’t it be nice ?
There are some people who obviously derided that new feature, calling it a ‘TODO app’. I get it. It’s pretty basic for now. But keep in mind that the rate of improvement is probably going to be significant.
In a sense, we are slowly entering level 3 of the 5 stages of Artificial Intelligence. You read it from me before, 2025 is probably going to be big for AI agents. With the o series of models and similar program synthesis initiatives, enormous progress is currently being done on the path to strong reasoners.
In parallel, a lot of initiatives around agentic systems focus on architectures that allow AIs to take action (send a reminder, check emails, etc.). These parallel efforts will merge as soon as we get stronger reasoners outside of coding and math. At that point, building powerful agents will feel easy and inevitable. Building innovators will also feel easy and inevitable. Moving from level 4 to level 5 will then just be a question of change management. Humans will be the biggest bottleneck, as it should be. After all, we don’t want rogue AIs doing things that could be detrimental to humanity.

Exciting stuff. Let’s get back to regular programming.
The Flux Is Coming
As an extensive user of the Nebius AI Studio, I got to play with some of the text to image (TTI) models they will be shipping soon: Flux Schnell, Flux Dev, and SDXL. These three models are impressive and SOTA.
Most people (including developers) seem stuck at the LLM level. I get it. Everything started with them LLMs. But goddammit, how long are we going to ignore the power of TTI models, especially since they’ve improved so much in the past two years ?

The reality is that prompting LLMs is easier than prompting TTI models. Anticipating the results of LLM calls is also easier. To properly prompt TTI models you need to imagine and describe the most clearly possible the image you want to get. You have to think about the subject, the medium, the environment, the lighting, the color, the mood, the composition. That requires much more effort. Add the fact that there is also a specific jargon you often have to learn to elicit the kind of response you need (‘realistic’, ‘closeup’, ‘overcast’, etc.), and the result is less general usage except from niche communities (designers, photographers etc.).
Still, I am here to tell you to start tinkering with TTI models. Maybe you need images for a presentation you are working on. Maybe you need assets for your next ad campaign. TTI models can help you iterate on design ideas. And in a world where appearance often trumps everything else, an AI generated image is maybe the missing piece you need to shine (haha, half joking here).
Let’s talk price for a minute. I have said it before. AI models will become commodities over time. It’s practically already the case, just look at the price drops since November 2023. TTI models also follow that trend. The Nebius AI Studio offers the optimal choice across Flux Schnell, Flux Dev, and SDXL, with unmatched affordability, exceptional flexibility, and blazingly fast generation speeds.
In the Nebius AI Studio, generating 1000 images will only cost you $1.3 if you use Flux Schnell, $7 if you use Flux Dev, and $3 if you use SDXL. That’s the cheapest prices for each model you will get among model providers (Replicate, FAL, and Fireworks are more expensive).
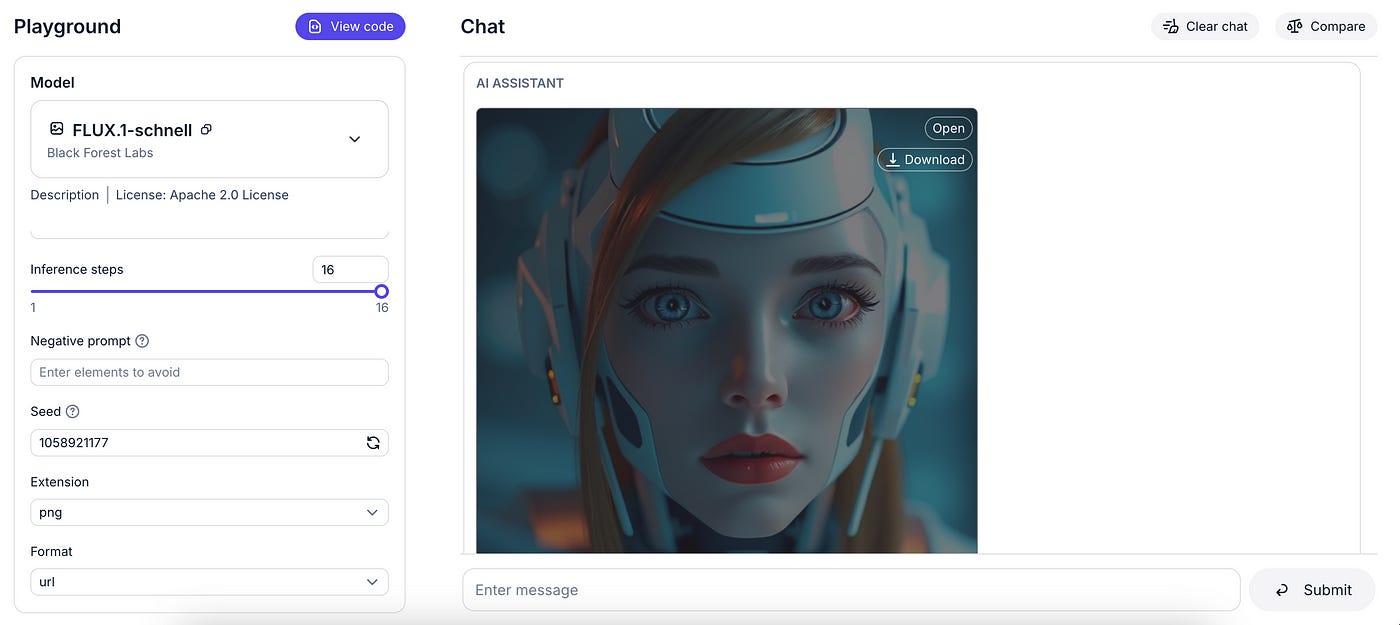
I recently built a website to help people learn how to prompt TTI models. Give it a try. Here is the link:
Here is how to use the app. It is pretty straightforward:
Try and let me know what you think.
Happy prompting !
I must check out Nebius, it’s been on my list. I use Replicate a LOT so I’m interested in alternatives if they’re cheaper.