


GPT-4.5 Is a Flop
Pretraining has hit a wall, and Sam Altman was wrong.

OpenAI finally released its biggest model yet: GPT-4.5. And it’s a flop.
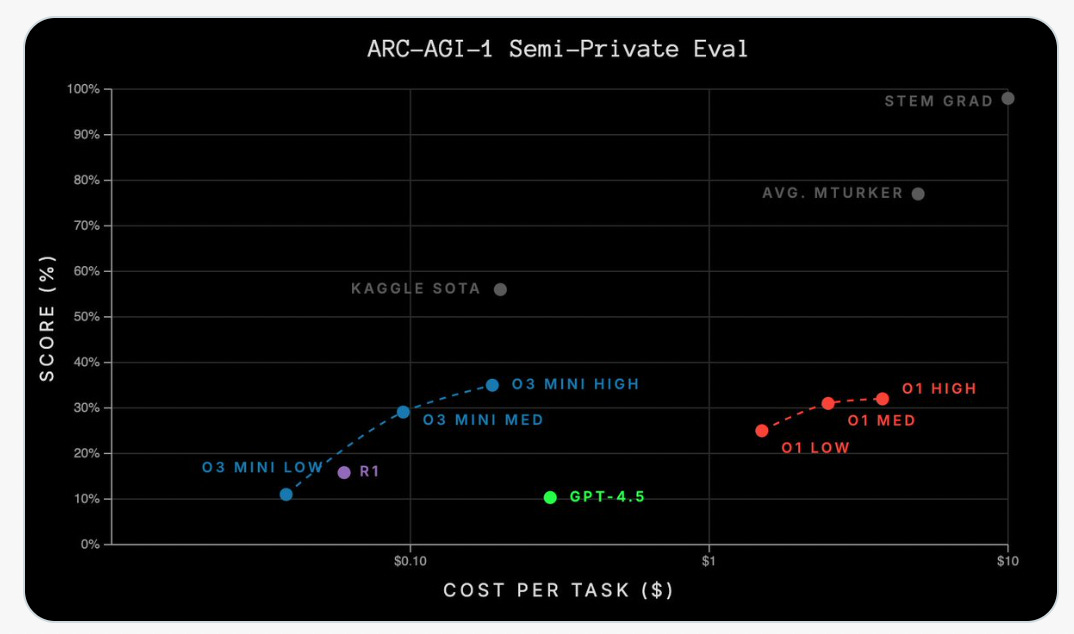
It’s a flop because OpenAI built up so much anticipation about it for months, just for everyone to realize how mid it is in terms of performance. Look at the ARC-AGI semi-private evaluation above — GPT-4.5 is almost at the exact same level GPT-4o was. That doesn’t seem like an increase in intelligence, does it?
OpenAI’s response has been to say GPT-4.5 is not a reasoning model but a classic model that went through pretraining, supervised fine-tuning, and reinforcement learning with human feedback. As such, we should not expect it to thrive on benchmarks but rather to exhibit better creative writing skills and a much stronger grasp of facts (less hallucination).
But if that’s the case, why hype it up so much? Why release it now with pricing so absurd that developers will just skip using it? The messaging around GPT-4.5 has been clumsy at best. I feel like this is the first timing mistake from OpenAI.
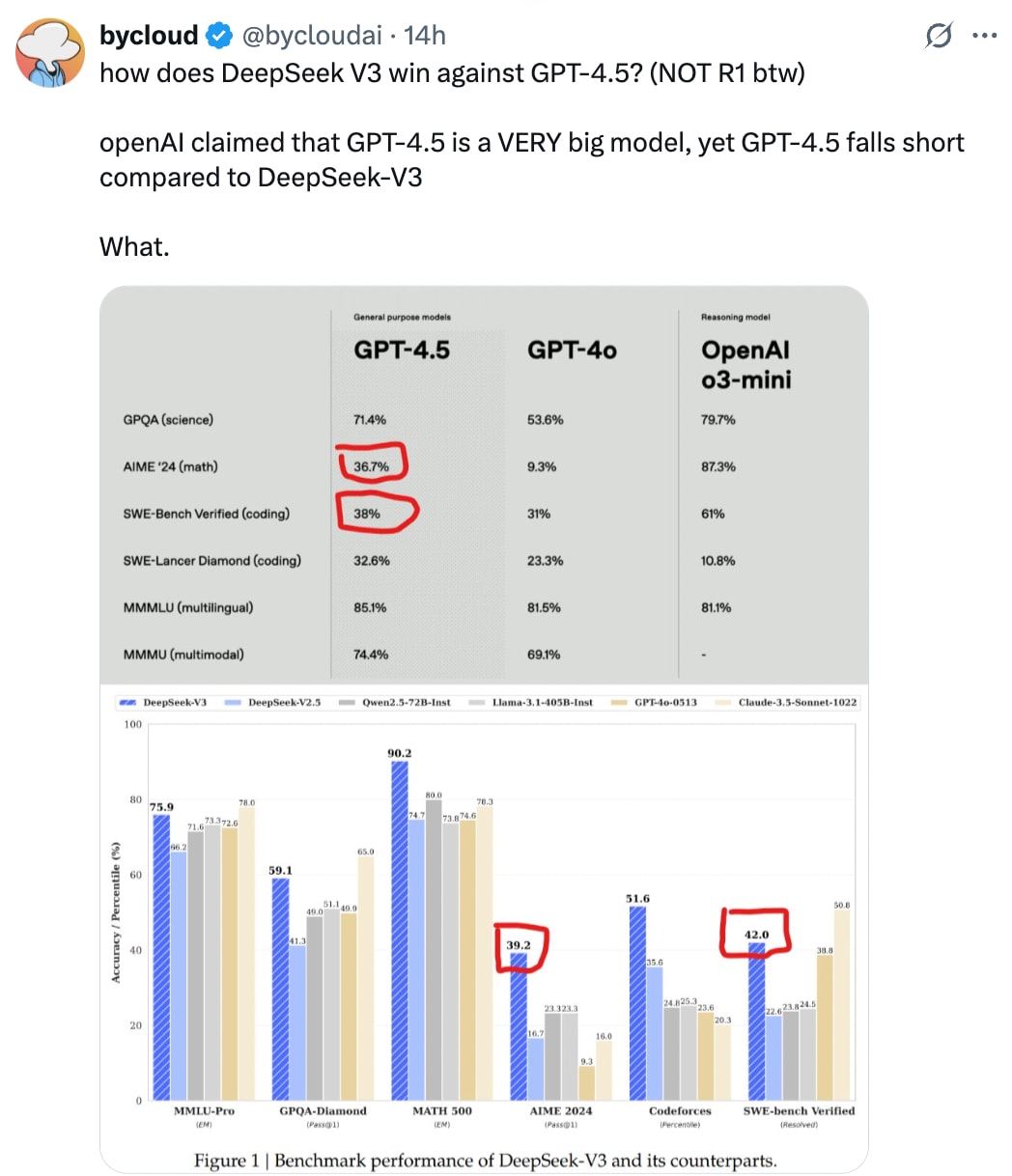
And the argument that it is just a bigger GPT model that will later yield better reasoning models doesn’t even hold. DeepSeek-V3, a similar type of model — if we want to make apple-to-apple comparisons — is still better than GPT-4.5 on benchmarks like AIME and SWE-bench verified while being way cheaper, as pointed out by this anonymous X account.
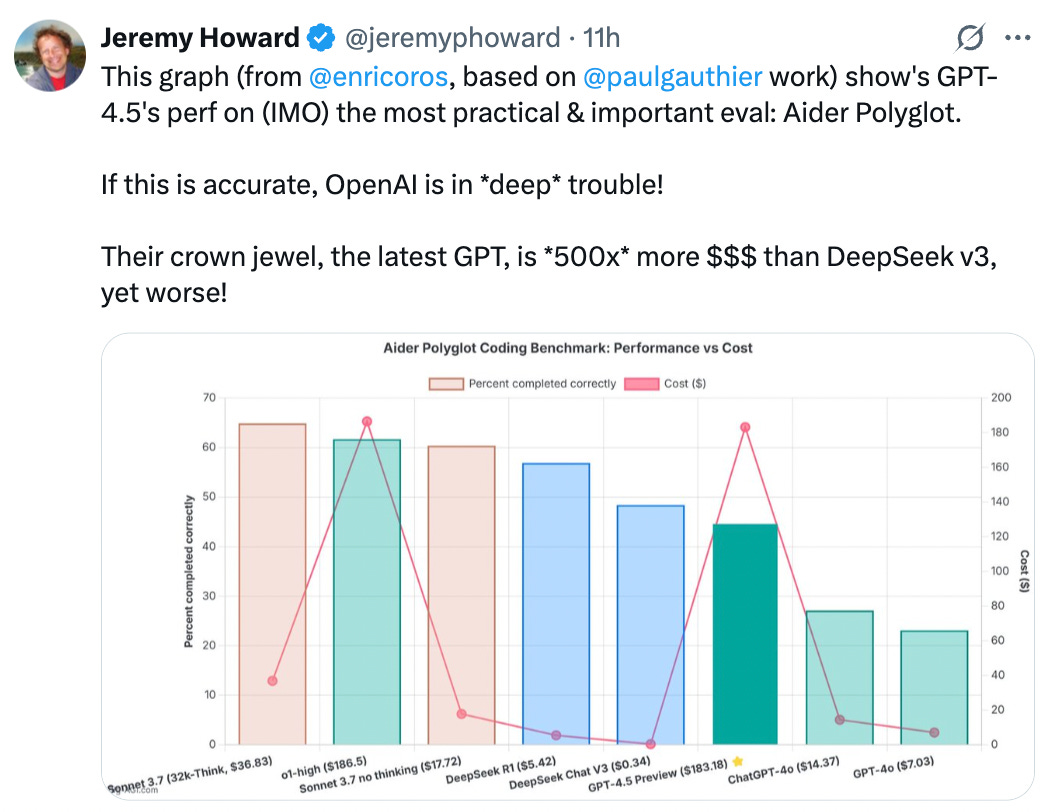
Jeremy Howard also pointed out that the current performance of GPT-4.5 on Aider Polyglot, a robust coding benchmark, might indicate that OpenAI is in “deep trouble.”
So I, like many others in the AI space, am left wondering: Why did they release it now? What did they expect to achieve by releasing it now, and what does it say about what comes next in the AI space?
I have a theory.

Keep reading with a 7-day free trial
Subscribe to Transitions to keep reading this post and get 7 days of free access to the full post archives.